Data Vault Modeling Patterns (2/2)
Dealing with headers, line items and lookup values

Welcome to the second issue of Model Your Reality, a newsletter with musings about data modeling, data warehousing and the like.
Until further notice, each issue will contain of two parts:
a list of upcoming data events that might be of interest for you (they definitely are of interest for me) and
some thoughts about a certain data topic (like data vault modeling patterns).
Let’s get started!
Upcoming Data Events
If you know about other relevant events in the near future, please mention them in the comments or send an email to admin@obaysch.net.
2021-12-07/09: Data Vault Training (CDVDM), Genesee Academy (online & Stockholm)
2021-12-08: dbtvault Meetup (online)
2021-12-14: Data Modeling Meetup with Francesco Puppini (online)
2022-02-08: Data Modeling Meetup with Michael Müller (online)
2022-06-01/03: Knowledge Gap data modeling & data architecture conference (online)
Data Vault Modeling Patterns (2/2)
If you’re new to the topic or don’t have a lot of practical data vault experience, you might want to consult my series of articles on Modern Data Warehousing with Data Vault here or have a look at one of the books recommended in the Data Vault section here to get the most out of this section.
Introduction
When building a data vault model, you encounter some of the same situations again and again. Therefore it is good to have something similar to the structural conventions described here so that you deal with these situations in a consistent manner.
The data vault modeling patterns described in this little series will help you to achieve this consistency by recognizing standard situations and sticking to standard solutions for resolving them.
In the previous issue, we looked at some of the finer points of link design, modeling hierarchies (when one instance is subordinate to another) and modeling identity (when two instances actually refer to the same thing). In this issue, we will look at modeling headers and line items and handling lookup values.
To raise awareness of these data vault modeling patterns and to point out the standard solution for a certain situation, consider creating some documentation similar to the one for the structural conventions. Your successors will thank you.
Header and Line Items
Headers and line items are a very common use case that should be dealt with consistently.
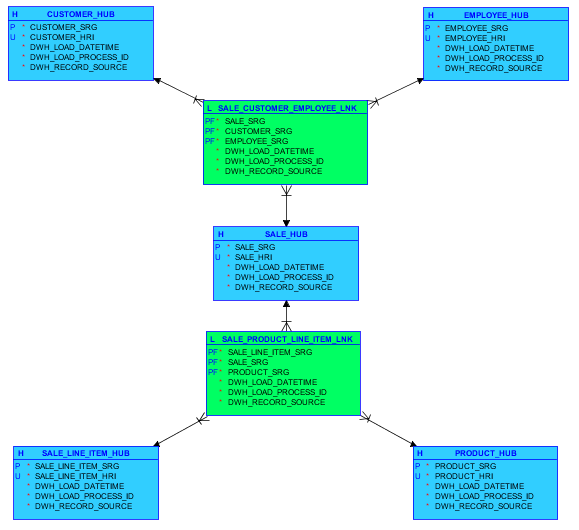
One Type of Line Items (“Dogbone”)
The classic header–one type of line items situation appears when there is an event, often but not always a transaction, that involves multiple instances of some other concept:
a Sale event involving multiple Products,
a Delivery event involving multiple Products,
a DWH Load Process event involving multiple DWH Tables or
a Surgery event involving multiple Surgical Steps.
In this situation, there usually are two connections involving the respective event, one at the header level (e. g., connecting the Sale to a Customer, an Employee and a Store) and the other at the line item level (e. g., connecting the Sale to the Products that have been sold).
In general, the link at the line item level includes a keyed-instance hub. In the Sale example, the Sale Line Item hub would contain a human-readable identifier consisting of the human-readable identifier of the parent Sale and a sequential number. A satellite attached to this hub would contain attributes like quantity and actual unit price (as opposed to the list price of the Product sold).
While in some cases, you might get away with omitting the keyed-instance hub and storing the line item details in a link satellite, the keyed-instance hub is the preferable modeling option because it can easily deal with events involving multiple instances of the same concept (e. g., a Sale where a Product is sold three times, the first two times at the list price and the third time at 50 % the list price because of a promotion) and connections to specific line items (e. g., a Delivery including some Sale Line Items from a Sale but not others).
Because the resulting model tends to look like one, the header–one type of line items pattern is sometimes referred to as the dogbone pattern.
Two Types of Line Items (“Wishbone”)
Some events are more complex and involve instances of two other concepts:
a Car Repair event involving multiple Parts and multiple Service Actions,
a Surgery event involving multiple Drugs and multiple Surgical Steps or
a Car Accident event involving multiple damaged Cars and multiple injured Road Users.
In this situation, there usually is one connection at the header level (e. g., connecting the Car Repair event to the Workshop where the Car is repaired and to the Car itself) and two different connections at the line item level. In the Car Repair example, one line item connection would connect the Car Repair event to the Parts used and the other line item connection would connect the Car Repair event to the Service Actions executed.
For multiple types of line items, the same reasoning about keyed-instance hubs applies as in the one-type-of-line-items case. If you look at all three examples mentioned at the beginning of this section in combination, you can see the usefulness of keyed-instance hubs for connecting the different events (as might be necessary for the insurance company handling the Car Accident):
A Car Repair is necessary for a certain Car that has been damaged in a specific Car Accident. If you have applied this pattern with a keyed-instance hub, you can easily connect the Car Repair event to the Car Accident Damaged Car Line Item.
A Surgery is necessary for a certain Road User that has been injured in a specific Car Accident. If you have applied this pattern with a keyed-instance hub, you can easily connect the Surgery event to the Car Accident Injured Road User Line Item.
Because the resulting model tends to look like one, the header–two types of line items pattern is sometimes referred to as the wishbone pattern.
More Than Two Types of Line Items
While events involving instances of three or more other concepts might seem unusual at first glance, they are more common than one might think:
A Surgery can involve multiple Drugs, multiple Surgical Steps, multiple Surgical Instruments, multiple Nurses and multiple Surgeons.
A Car Accident can involve damaged Cars, multiple injured Road Users, multiple Road Users that have witnessed the event, multiple Police Officers and multiple damaged Roadside Objects (streetlights, guard rails and so on).
The reasoning from the previous sections applies accordingly: There usually is a connection at the header level (which translates into a link) and three or more different connections at the line item level (each of which translates into a link with a keyed-instance hub).
Lookups
Lookups are the final common use case we’ll look at in this issue.
Put simply, a lookup works like this: There is a code or surrogate identifier in one table (e. g., a status code) and you can look up the description for that code in another table (that contains, in our example, all possible status codes with the respective descriptions).
In a data vault model, there are several different options for handling lookups. Often, it is possible to simply put code and description in the same satellite. Sometimes, code and description are actually details about some other concept. Then, it makes sense to put them in a satellite attached to a hub standing for that new concept. And finally, you might create a reference table that contains code and description.
When you create a new hub with a satellite for lookup data, you can either create an actual link to the new hub or use the so-called disconnected pattern. In this case, you just put the code in the existing satellite and then join directly to the code in the new hub (or its satellite) to find the corresponding description instead of using a link. That way, you save yourself the effort of building and loading a link (and possibly a join). This approach isn’t completely aligned with the usual data vault principles but it’s an exception you might want to make for this limited use case.

In all likelihood, you will use more than one of the options described above in your model. But analogously to the different data vault constructs, you should think about how many options you really need. If all possible options are used interchangeably, the resulting model will get confusing for future core layer modelers and people loading data to the presentation layer alike.
Outlook
While data vault is a great choice for the core layer of your data warehouse, a data vault model with its large number of objects isn’t necessarily the most accessible way of presenting data to human users and other downstream consumers.
For each use case, try to pick the simplest presentation mode that meets your requirements. If current snapshots are all your consumers need, don’t give them bitemporal historization.
We’ll start looking at presentation modes in more detail in one of the next issues of Model Your Reality.